
 |
By David Flack (University of Reading) 18th January 2016 |
{kind=link}
In my previous blog I talked about the different convective regimes that flash floods occur in, and was in the early stages of my PhD. My work has moved on a fair amount since then and I have started to look into ensemble forecasts of convective events. I have spent a fair amount of my PhD working out a design for a convection-permitting ensemble, so I thought I’d write a bit about the process to help show the uncertainties we currently face in predicting thunderstorms.
Now, ensembles (and their uses) have been covered a fair amount in this blog, as have advances in forecasting in which it was mentioned that probabilistic forecasts could be made from well-spread ensembles that take into account the true uncertainties in a forecast. But one of the key questions in convection-permitting ensemble research groups is how do we represent the uncertainties?
This question has many answers, I suggest here a couple of ways in which we could look at the uncertainties, but before I do I will give a brief reminder of what an ensemble is and how it works. Traditionally a model would be run with one realisation in a deterministic fashion, and that would be the forecast. However, is we were to nudge (perturb) the starting conditions, model physics or boundary conditions (or all three) of the run we could (provided the ensemble is well-spread) create equally likely outcomes and hence a probabilistic forecast of whether or not is would rain tomorrow (Fig. 1).

Fig.1: Deterministic and ensemble forecast, dark red crosses show the starting and ending positions of the forecast and the bright red cross shows the truth. The dotted lines show the path of the forecasts and the red circles indicate the range of starting positions and possible forecasts.
So how can we try to take into account the uncertainties? Well to start to answer that we need to know what could be uncertain about a forecast, three things come to mind immediately – the location, the timing and the intensity of rainfall.
How can we take some of these things into account? Well I mentioned earlier we could change the initial and boundary conditions of the model – this could be done by a process of time lagging, by which we look at previous forecasts and create an ensemble member over times that they all cover (Fig. 2) this may give an idea into when the convection could actually occur, and may even go some way to changing the position and or intensity of the event.
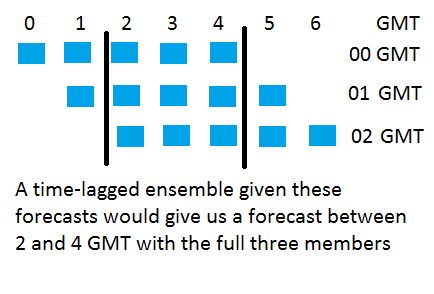
Fig. 2: Time-Lagged ensemble schematic. For a forecast initiated at 00, 01 and 02 GMT we can create an ensemble for 2 – 4 GMT based on the data points shown between the two black lines.
We could also take the option of tweaking the model physics slightly, we could do this by adding a field of random numbers every so often into model and run these new numbers through the model, we could use different parameterisations or using aspects of the behaviour of the event we are trying to forecast, like add stochastic noise into a process that is stochastic in nature.
These suggestions are just a couple of ways of taking into account uncertainty. I am by no means claiming these are the best ways or the only ways, and they certainly do not take into account the full uncertainty in the atmosphere, but at least it’s a start in the right direction. However, these types of differences do produce different realisations of the atmosphere and hence different forecasts for rainfall events, so can be used in giving us probabilistic forecasts of flash floods and other events.
The next thing to concern us though is how do we actually interpret, communicate and verify probabilistic forecasts, but this is a completely different topic which I will not cover in this blog. However, to give you a clue it takes more than one forecast to verify a probability.
Is the ensemble used for flood control?