Computers are no longer getting faster, they are just getting bigger. So in order to be able to do more detailed and accurate weather and climate simulations, models must be able to run efficiently on massively parallel computers. There has been alot of effort recently optimising the Met Office Unified Model (UM) (unified for weather and climate) which can now run efficiently on 14,000 processing cores. But this is still not enough. More detailed climate predictions may need 100,000 or even a million cores. The GungHo project is joint between the Met Office, a number of NERC funded academics and STFC to design a new model without the bottlenecks that are currently limiting model performance.
Why won’t the existing model scale to more processing cores?
In order to simulate the climate on a large number of cores, the atmosphere and ocean are decomposed into lots of regions and each region is simulated on a different core. These must all communicate so that the weather in one region influences neighbouring regions. A model scales well if, when you decompose the model domain into, say, 10,000 regions and run on 10,000 cores, the model runs nearly 10,000 times as fast as if you ran on one core. One of the first bottlenecks is input and output (IO). When the model finishes a period of its simulation and needs to write out the results, all the data is sent to one processor to be written out to disk. This can be overcome using temporary storage local to each processor. There are also bottlenecks that are more fundamental to the design of the climate model and these are the subject of research during the GungHo project.
Problems with the Latitude-Longitude Grid
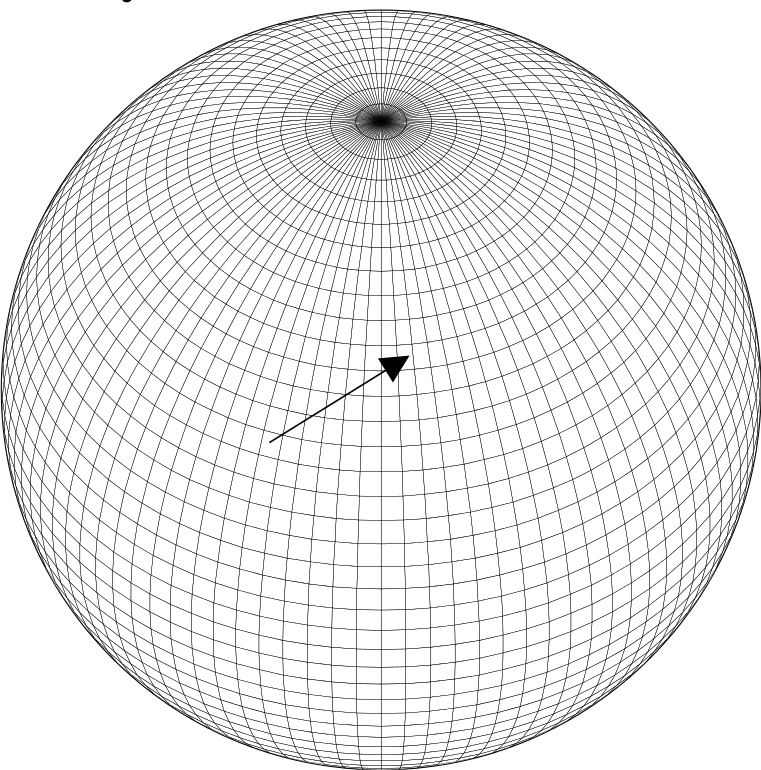
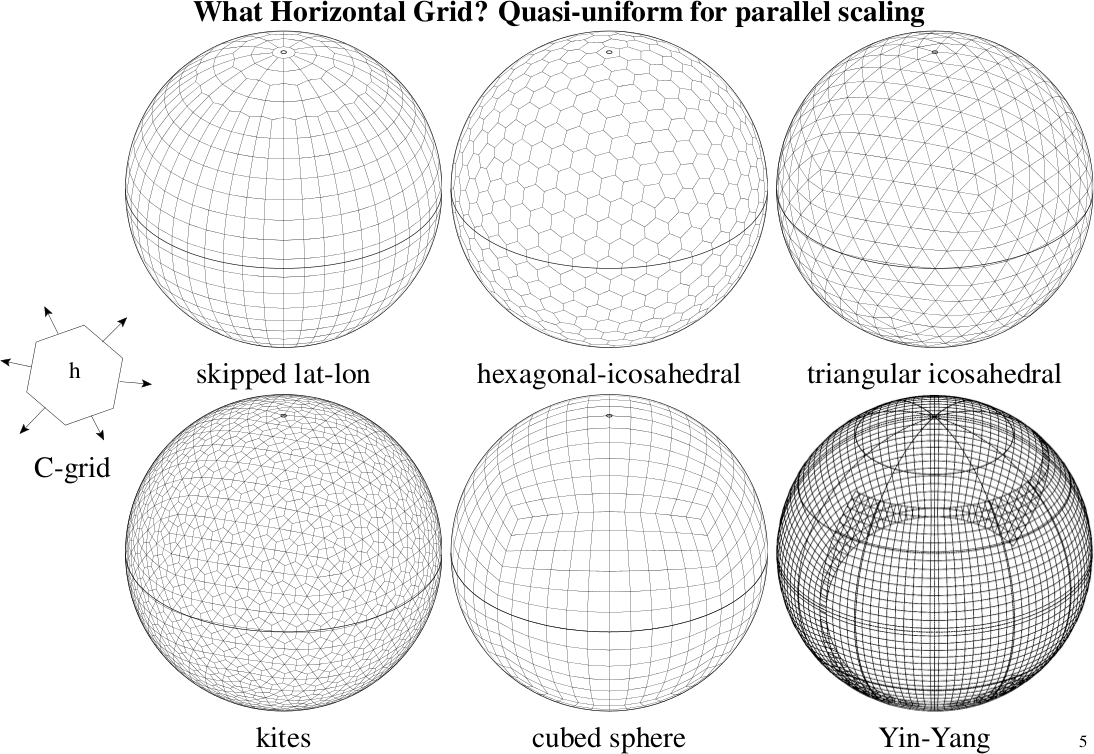
The weather in one location is influenced by its surroundings. The size of the “surroundings” is dependent on the model time-step. Towards the poles of the latitude-longitude grid many grid-points are clustered together so if I live at 89 degrees north, many grid-points will influence my weather. These grid-points may be distributed over many different processing cores and so each must communicate their weather to my core in order for my weather to be predicted. This inevitably leads to a lot of communication and so the forecasting models on each core end up waiting for data from their surroundings. Consequently, various quasi-uniform grids are being considered and studied for the next generation Unified Model (see figure).
Semi-implicit time-stepping
The efficiency of a model is related to the largest possible time-step that can be taken. If a very large time-step is used then the model will finish its forecast more quickly. If it doesn’t crash in the process. Large time-steps can make models blow up if you are trying to propagate a wave or move some mass by more than one grid box in a time-step. The fastest waves simulated by climate models are sound waves. We do not want the model time-step to be restricted by the time taken for a sound-wave to travel from one grid-box to the next. So instead of solving the sound-waves explicitly, moving them by just one grid-box every time step, they are solved implicitly, which requires a simultaneous solution over every grid-box of the equations governing their motion. This removes the time-step restriction based on sound waves which enables a model to take much longer time-steps and therefore complete its forecast more quickly. But the simultaneous solution over all grid-points means global communication which will limit parallel scaling. In GungHo we are investigating linear equation solvers which are more efficient on many cores (to solve the simultaneous equations) and we are also considering only solving the equations simultaneously in the vertical direction and not the horizontal direction. The vertical grid-spacing is much smaller than the horizontal grid-spacing (by perhaps a factor of 1000) so if we can remove the time-step restrictions based on the speed of sound in just the vertical direction then this might be sufficient to allow long enough time steps to finish the forecast in time while not requiring global communication which slows down a model running on 100,000 cores.
Semi-Lagrangian advection
To be able to take even longer time-steps and thus finish a forecast even more quickly, semi-Lagrangian advection is used in many advanced weather forecasting models. Rather than propagating information from one grid-box to the next, the properties of the atmosphere (temperature, velocity, moisture content etc) are moved a long distance in one time-step. In order to predict the conditions at any grid-box at the new time-step, the winds from the old time-step are used to calculate an approximate departure point. Ie where did the atmosphere come from to arrive at this grid-box at the new time step. The conditions at the old time-step are then interpolated onto the departure point and moved to the current grid-box. Semi-Lagrangian advection allows much longer, stable and accurate time-steps. But it seems that any advanced technique that allows longer time-steps will also limit parallel scaling. The departure point may be on a different processing core or even (near the pole) not the next core along but the one after that. Therefore alot of communication is needed for semi-Lagrangian advection and the advantages may be lost when moving to massively parallel computers. The GungHo project is therefore investigating alternatives, such as “Auxiliary semi-Lagrangian” which basically means advecting the properties one grid-box at a time but using lots of small sub time-steps.
It is possible that the next version of the UM will still use semi-implicit time-stepping, semi-Lagrangian advection but will use the Yin-Yang (overlapping) grid (see figure). The one after may look very different, perhaps on an icosahedral grid with an option for implicit time-stepping only in the vertical and without semi-Lagrangian advection.