Climate scientists from around the world have spent the last few years preparing for, and now running and analysing the results for the fifth global climate model intercomparison project (CMIP5). The aim of CMIP5 is to get many (eventually in excess of twenty) modelling groups to run simulations of past and future climate that conform to a set of prescribed experiments – by comparing the results from this “multi-model” activity, one can both learn about the physics of climate and have more confidence in the simulations themselves. The experiments are broadly targeted at addressing outstanding scientific questions (especially those which arose from the last IPCC assessment report) and providing estimates of future climate change. The latter include both traditional “hundred-year-plus” experiments like those analysed in previous intercomparison projects, and some new “out there” experiments aimed at finding out how good (or bad) we are at prediction on decadal timescales (and how we might improve them).
The climate science results are still to come from CMIP5, but there have been a raft of computing problems solved (and yet to be solved) in delivering CMIP5.
Firstly, and most obviously, each modelling group has been improving their models so their simulations can both tell us more about climate mechanisms and be more useful for prediction. These models have to target a huge range of experiments, the full details can be found here, but a flavour of the diversity can be seen in this figure (from Karl Taylor) showing just the long-term experiments:
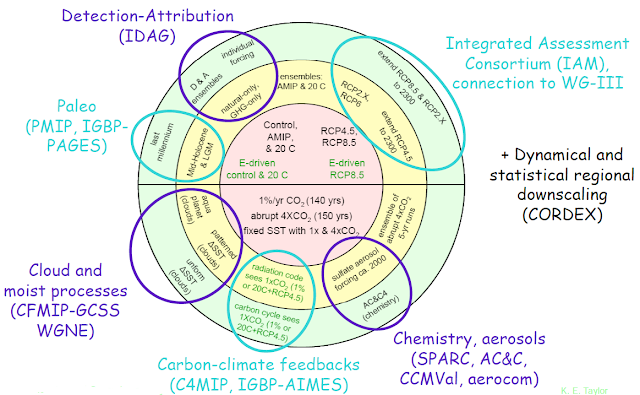
Apart being an acronym-fest, the clear take home message from this figure is the diversity of activities being supported within CMIP5 – from what are essentially physics experiments (the lower half) such as the “Cloud Forecasting Model Intercomparison Project” (CFMIP) and the Stratospheric Processes and their Role in Climate (SPARC) activity – to the projections and hindcasts (the top half) which are aimed at projecting future climate (and evaluating the likely fidelity of those projections).
It’s been a challenge for nearly every modelling group: getting the models improved and evaluated, and then used to carry out many experiments on a very aggressive timescale (everyone wanted the main simulations done in time so that the analysis of key results can be done, and published, in time for incorporation in the next IPCC assessment report). Most models have more complexity and higher resolution, and are being run with bigger ensembles, and while faster computers have helped with that, in practice, most groups have also been solving itty-bitty performance problems “under the hood” – resulting in hard won progress from sophisticated software engineering and computer science. They’ve also been dealing with stupid output data volumes : the Met Office alone is expecting to produce over 50 terabytes of data – roughly half as much data again than all the modelling groups in the world produced for the last global model intercomparison project (CMIP3 in 2006).
The often forgotten “ugly sister” of the climate computing problem is the data handling: in truth I don’t know how many folk are involved in the data pipeline from the Met Office supercomputer, but I’m sure there are at least five folks involved before the data hits a publicly visible website! Similar teams exist in every big modelling group. I sometimes think of climate computers and their running models as data hosepipes. It’s a useful analogy because it reminds us that if you leave the hose on, you need to worry about where all that water is going …
That’s the “modellers-eye-view”, but there’s another perspective, that of the “users” of all this data – some of whom are obviously the same folk who ran the experiments. The users have to get at all this data, understand which model ran what (and what the model capabilities were), and then, and only then can they do the science. Stretching the hosepipe analogy means they’ll be faced with a swimming pool of data – many petabytes of the stuff! If you think of a dataset as being one variable, produced by one model, for one experiment, then we expect millions of such datasets!
It doesn’t take much thinking about that to realise that the “information management” problem for CMIP5 is just as big as the modelling problem: how to record and display information about the data, alongside the data? How to make the data easily downloadable around the planet? How to avoid those petabytes of data crossing the Atlantic more times than necessary? How to get systems set up that cross national borders, and that have components built by teams all around the globe? Answering those questions has been a blend of research and both social and software engineering!
The resulting information systems are complex, and right now a wee bit more immature than any of us would like (i.e. not yet as efficient and reliable as we expect) – but you can see the British gateway to CMIP5 here – just one node in a global federation of data nodes and gateways, the “Earth System Grid Federation”. Those information systems are backed up by teams of people working on the software to sustain it (more pipes) and adding and moving content (to “replicate” core content at key sites). There is even a quality control system in place aiming to eventually provide a formal publication process for the CMIP5 data.
While the eventual size of the CMIP5 data archive is expected to be many many petabytes, as of the time of writing (the current status is here), there are over 500 terabytes of data in over one million files from 17 modelling centres and 30 different models! I like to think of that archive as a swimming pool of data being filled by many many hosepipes (ok, like all analogies, it’s flawed … maybe multiple swimming pools connected by pipes … fed by hose pipes … oh stop it Bryan …)
I also like to think that, despite it’s flaws, the information system supporting the CMIP5 archive is an amazing achievement – both socially and technically. Now, like many of my colleagues, I hope to stop thinking about the CMIP5 process, and start thinking about the CMIP5 science (but yes, more data will appear, and the information systems will keep on improving)!