In 2020 56% of the global population lived in cities and towns, and they accounted for two-thirds of global energy consumption and over 70% of CO2 emissions. The share of the global population living in urban areas is expected to rise to almost 70% in 2050 (World Energy Outlook 2021). This rapid urbanization is happening at the same time that climate change is becoming an increasingly pressing issue. Urbanization and climate change both directly impact each other and strengthen the already-large impact of climate change on our lives. Urbanization dramatically changes the landscape, with increased volume of buildings and paved/sealed surfaces, and therefore the surface energy balance of a region. The introduction of more buildings, roads, vehicles, and a large population density all have dramatic effects on the urban climate, therefore to fully understand how these impacts intertwine with those of climate change, it is key to model the urban climate correctly.
Modelling an urban climate has a number of unique challenges and considerations. Anthropogenic heat flux (QF) is an aspect of the surface energy balance which is unique to urban areas. Modelling this aspect of urban climate requires input data on heat released from activities linked to three aspects of QF: building (QF,B), transport (QF,T) and human/animal metabolism (QF,M). All of these are impacted by human behaviour which is a challenge to predict, as it changes based on many variables, and typical behaviour can change based on unexpected events, such as transport strikes, or extreme weather conditions, which are both becoming increasingly relevant worries in the UK.
DAVE (Dynamic Anthropogenic actiVities and feedback to Emissions) is an agent-based model (ABM) which is being developed as part of the ERC urbisphere and NERC APEx projects to model QF and impacts of other emissions (e.g. air quality), in various cities across the world (London, Berlin, Paris, Nairobi, Beijing, and more). Here, we treat city spatial units (500 m x 500 m, Figure 1) as the agents in this agent-based model. Each spatial unit holds properties related to the buildings and citizen presence (at different times) in the grid. QF can be calculated for each spatial unit by combining the energy emissions from QF,B, QF,T, and QF,M within a grid. As human behaviour modifies these fluxes, the calculation needs to capture the spatial and temporal variability of people’s activities changing in response to their ‘normal’ and other events.
To run DAVE for London (as a first test case, with other cities to follow), extensive data mining has been carried out to model typical human activities and their variable behaviour as accurately as possible. The variation in building morphology (or form) and function, the many different transport systems, meteorology, and data on typical human activities, are all needed to allow human behaviour to drive the calculation of QF, incorporating dynamic responses to environmental conditions.
DAVE is a second generation ABM, like its predecessor it uses time use surveys to generate statistical probabilities which govern the behaviour of modelled citizens (Capel-Timms et al. 2020). The time use survey diarists document their daily activities every 10 minutes. Travel and building energy models are incorporated to calculate QF,B and QF,T. The building energy model, STEBBS (Simplified Thermal Energy Balance for Building Scheme) (Capel-Timms et al. 2020), takes into account the thermal characteristics and morphology of building stock in each 500 m x 500 m spatial unit area in London. The energy demand linked to different activities carried out by people (informed by time use surveys) impacts the energy use and from this anthropogenic heat flux from building energy use fluxes (Liu et al. 2022).
The transport model uses information about access to public transport (e.g. Fig. 1). As expected grids closer to stations have higher percentage of people using that travel mode. Other data used includes road densities, travel costs, and information on vehicle ownership and travel preferences to assign transport options to the modelled citizens when they travel.

Figure 1: Location of tube, train and bus stations/stops (dots) in London (500 m x 500 m grid resolution) with the relative percentage of people living in that grid who use that mode of transport (colour, lighter indicates higher percentage). Original data Sources: (ONS, 2014), (TfL, 2022)
An extensive amount of analysis and pre-processing of data are needed to run the model but this provides a rich resource for multiple MSc and Undergraduate student projects (past and current) to analyse different aspects of the building and transport data. For example, a current project is modelling people’s exposure to pollution, informed by data such as shown in Fig. 2, linked with moving to and between different modes of transport between home and work/school. Therefore the areas that should be used/avoided to reduce risk of health problems by exposure to air pollution.
 Figure 2: London (500 m x 500 m resolution) annual mean NO2 emissions (colour) with Congestion Charge Zone (CCZ, blue) and Ultra Low Emission Zone (ULEZ, pink). Data source: London Datastore, 2022
Figure 2: London (500 m x 500 m resolution) annual mean NO2 emissions (colour) with Congestion Charge Zone (CCZ, blue) and Ultra Low Emission Zone (ULEZ, pink). Data source: London Datastore, 2022
Future development and use of the model DAVE will allow for the consideration of many more unique aspects of urban environments and their impacts on the climate and people.
Acknowledgements: Thank you to Matthew Paskin and Denise Hertwig for providing the Figures included.

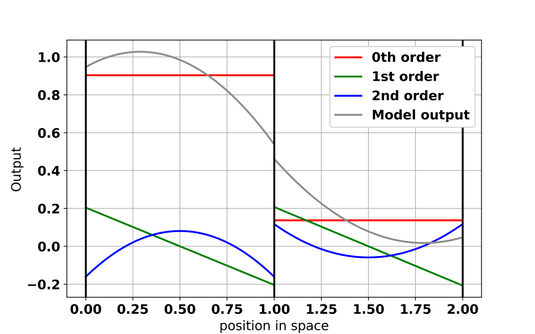
 To test the software, we need to consider whether the algorithm has made a reasonable attempt to place the cities from our dataset into clusters in our climate map. For those cities with which I am familiar, the map does appear to have clustered cities with similar temperature patterns together. The map colours indicate that we see larger regions made up of multiple cells containing generally warmer or cooler climates. In most but not all cases, cities from the same original region appear nearby in the new map – intuitively we would expect this.
To test the software, we need to consider whether the algorithm has made a reasonable attempt to place the cities from our dataset into clusters in our climate map. For those cities with which I am familiar, the map does appear to have clustered cities with similar temperature patterns together. The map colours indicate that we see larger regions made up of multiple cells containing generally warmer or cooler climates. In most but not all cases, cities from the same original region appear nearby in the new map – intuitively we would expect this.



 I am not sure where it got the idea of “low-topped” clouds from – this is outright wrong. The repetition of “convective” is not ideal as it adds no extra information. However, in broad strokes, this gives a reasonable description about the stratiform region of MCSs. Finally, here is a condensed version of both responses together, that could reasonably serve as the introduction to a student report on MCSs (after it had been carefully checked for correctness).
I am not sure where it got the idea of “low-topped” clouds from – this is outright wrong. The repetition of “convective” is not ideal as it adds no extra information. However, in broad strokes, this gives a reasonable description about the stratiform region of MCSs. Finally, here is a condensed version of both responses together, that could reasonably serve as the introduction to a student report on MCSs (after it had been carefully checked for correctness). There are no citations – this is a limitation of ChatGPT. A similar language model,
There are no citations – this is a limitation of ChatGPT. A similar language model, 

 The final task I tried was seeing if ChatGPT could manage a programming assignment from an “Introduction to Python” course that I demonstrated on. I used the instructions directly from the course handbook, with the only editing being that I stripped out any questions to do with interpretation of the results:
The final task I tried was seeing if ChatGPT could manage a programming assignment from an “Introduction to Python” course that I demonstrated on. I used the instructions directly from the course handbook, with the only editing being that I stripped out any questions to do with interpretation of the results: Here, ChatGPT’s performance was almost perfect. This was not an assessed assignment, but ChatGPT would have received close to full marks if it were. This is a simple, well-defined task, but it demonstrates that students may be able to use it to complete assignments. There is always the chance that the code it produces will contain bugs, as above, but when it works it is very impressive.
Here, ChatGPT’s performance was almost perfect. This was not an assessed assignment, but ChatGPT would have received close to full marks if it were. This is a simple, well-defined task, but it demonstrates that students may be able to use it to complete assignments. There is always the chance that the code it produces will contain bugs, as above, but when it works it is very impressive.


 Figure 1: (a) Charge sensor pod for MASC-3. Charge sensor (1, 2), painted with conductive graphite paint, and copper foil to reduce the influence of static charge build up on the aircraft. (b) MASC-3 aircraft with charge sensor pods mounted on each wing (8). The meteorological sensor payload is in the front for measuring the wind vector, temperature, and humidity (9). Figure from
Figure 1: (a) Charge sensor pod for MASC-3. Charge sensor (1, 2), painted with conductive graphite paint, and copper foil to reduce the influence of static charge build up on the aircraft. (b) MASC-3 aircraft with charge sensor pods mounted on each wing (8). The meteorological sensor payload is in the front for measuring the wind vector, temperature, and humidity (9). Figure from  Figure 2:. (a) Skywalker X8 aircraft on the ground. (b) X8 aircraft in flight, with instrumentation labelled. (c) Detail of the individual science instruments: (c1) optical cloud sensor, (c2) charge sensors, (c3a) thermodynamic (temperature and RH) sensors, (c3b) removable protective housing for thermodynamic sensors, and (c4) charge emitter electrode. Figure from
Figure 2:. (a) Skywalker X8 aircraft on the ground. (b) X8 aircraft in flight, with instrumentation labelled. (c) Detail of the individual science instruments: (c1) optical cloud sensor, (c2) charge sensors, (c3a) thermodynamic (temperature and RH) sensors, (c3b) removable protective housing for thermodynamic sensors, and (c4) charge emitter electrode. Figure from 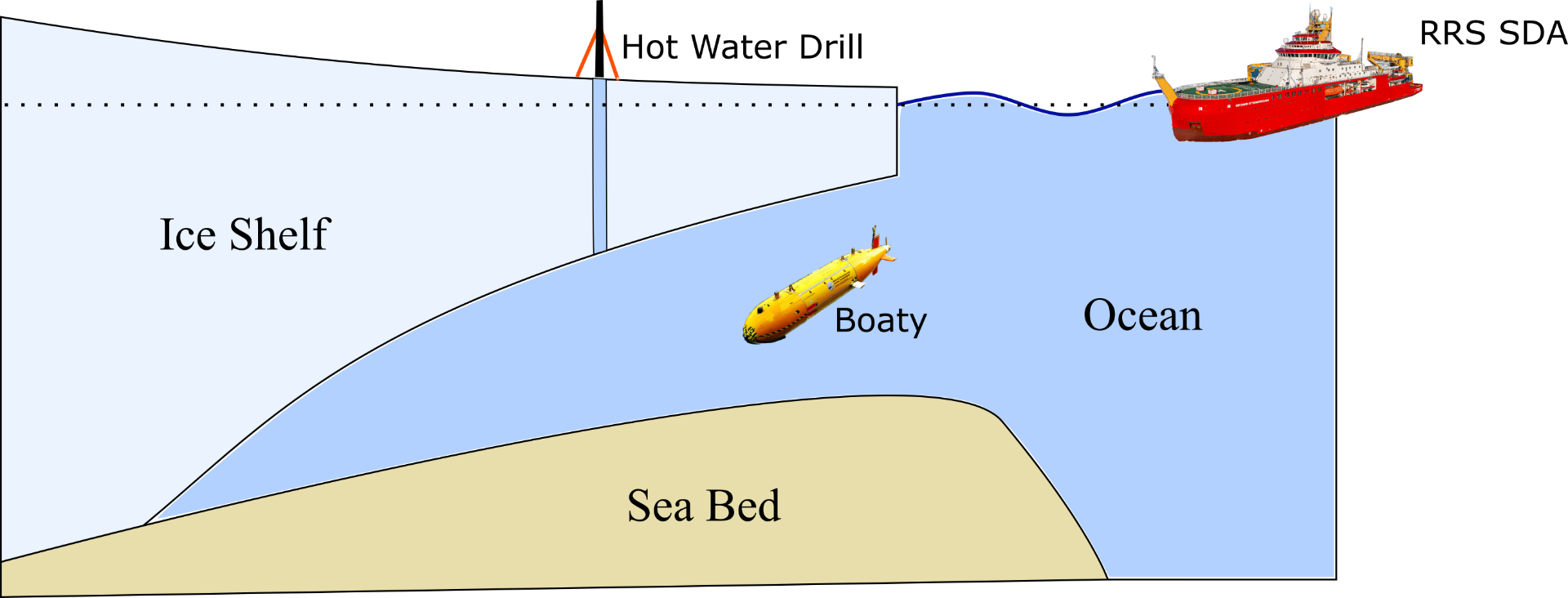
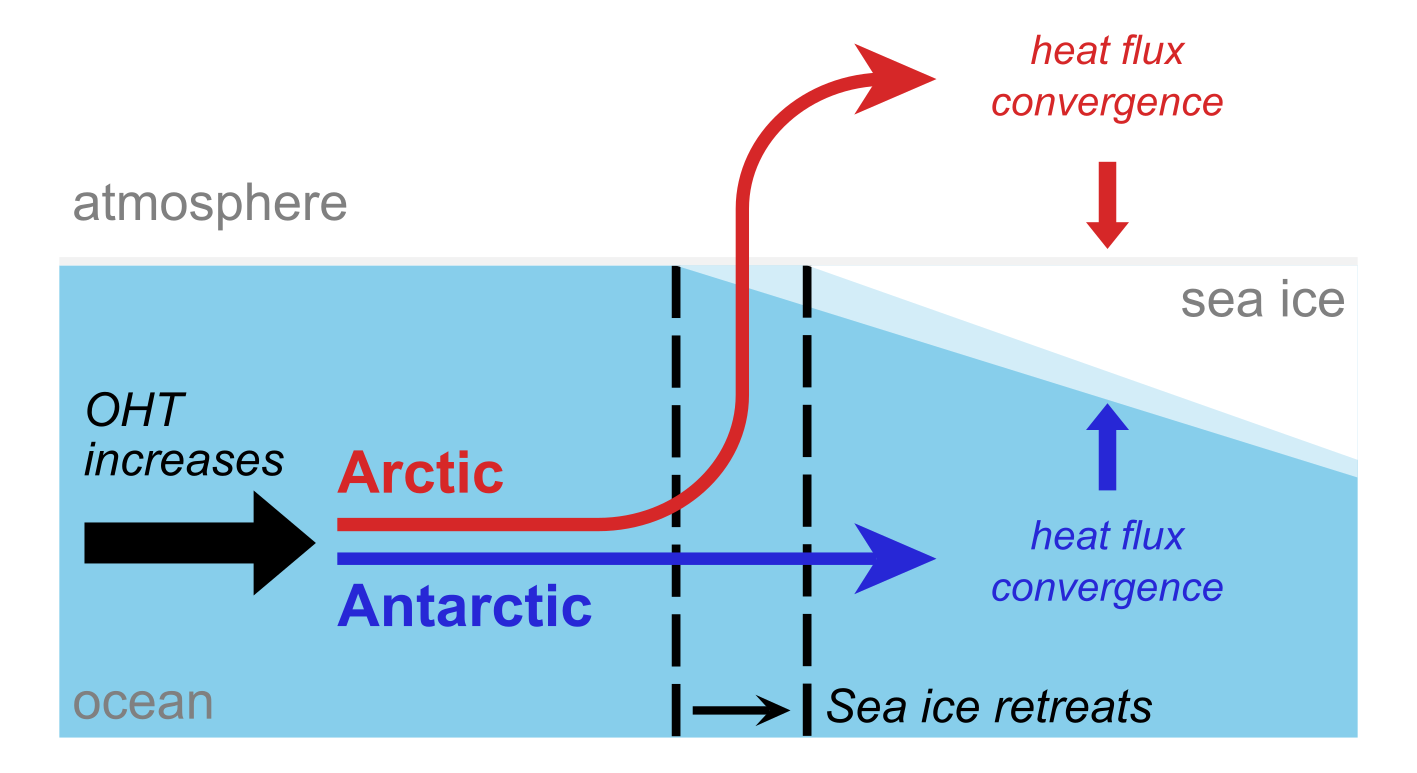 Figure 1: Different pathways by which extra ocean heat transport (OHT) reaches sea ice in the Arctic (red) where it is ‘bridged’ by the atmosphere to reach closer to north pole, compared to the Antarctic (dark blue), where it is simply released under the ice. Schematic adapted from
Figure 1: Different pathways by which extra ocean heat transport (OHT) reaches sea ice in the Arctic (red) where it is ‘bridged’ by the atmosphere to reach closer to north pole, compared to the Antarctic (dark blue), where it is simply released under the ice. Schematic adapted from